介绍
哈希表(Hash table,也叫散列表), 是根据关键码值(Key value)而直接进行访问的数据结构。也就是说,它通过把关键码值映射到表中一个位置来访问记录,以加快查找的速度。这个映射函数叫做散列函数,存放记录的数组叫做散列表。
哈希表hash table(key,value) 的做法其实很简单,就是把Key通过一个固定的算法函数既所谓的哈希函数转换成一个整型数字,然后就将该数字对数组长度进行取余,取余结果就当作数组的下标,将value存储在以该数字为下标的数组空间里。
而当使用哈希表进行查询的时候,就是再次使用哈希函数将key转换为对应的数组下标,并定位到该空间获取value,如此一来,就可以充分利用到数组的定位性能进行数据定位。
哈希表最大的优点,就是把数据的存储和查找消耗的时间大大降低,几乎可以看成是常数时间;而代价仅仅是消耗比较多的内存。然而在当前可利用内存越来越多的情况下,用空间换时间的做法是值得的。另外,编码比较容易也是它的特点之一。 哈希表又叫做散列表,分为“开散列” 和“闭散列”。
我们使用一个下标范围比较大的数组来存储元素。可以设计一个函数(哈希函数, 也叫做散列函数),使得每个元素的关键字都与一个函数值(即数组下标)相对应,于是用这个数组单元来存储这个元素;也可以简单的理解为,按照关键字为每一 个元素“分类”,然后将这个元素存储在相应“类”所对应的地方。
但是,不能够保证每个元素的关键字与函数值是一一对应的,因此极有可能出现对于不同的元素,却计算出了相同的函数值,这样就产生了“冲突”,换句话说,就是把不同的元素分在了相同的“类”之中。后面我们将看到一种解决“冲突”的简便做法。 总的来说,“直接定址”与“解决冲突”是哈希表的两大特点。
举例
这里先说一下哈希(hash)表的定义:哈希表是一种根据关键码去寻找值的数据映射结构,该结构通过把关键码映射的位置去寻找存放值的地方,说起来可能感觉有点复杂,我想我举个例子你就会明白了,最典型的的例子就是字典,大家估计小学的时候也用过不少新华字典吧,如果我想要获取“按”字详细信息,我肯定会去根据拼音an去查找 拼音索引(当然也可以是偏旁索引),我们首先去查an在字典的位置,查了一下得到“安”,结果如下。这过程就是键码映射,在公式里面,就是通过key去查找f(key)。其中,按就是关键字(key),f()就是字典索引,也就是哈希函数,查到的页码4就是哈希值。
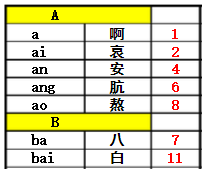
哈希函数的构造方法
根据前人经验,统计出如下几种常用hash函数的构造方法:
1.直接定址法
哈希函数为关键字的线性函数如 H(key)=a*key+b
这种构造方法比较简便,均匀,但是有很大限制,仅限于地址大小=关键字集合的情况
使用举例:
假设需要统计中国人口的年龄分布,以10为最小单元。今年是2018年,那么10岁以内的分布在2008-2018,20岁以内的分布在1998-2008……假设2018代表2018-2008直接的数据,那么关键字应该是2018,2008,1998……
那...
课后习题
【2019年真题】现有长度为11且初始为空的散列表HT,散列函数是H(key)=key%7,采用线性探查(线性探测再散列)法解决冲突将关键字序列87,40,30,6,11,22,98,20依次插入到HT后,HT查找失败的平均查找长度是
A. 4 B. 5.25 C. 6 D. 6.29
参考答案:C
【2018年真题】现有长度为7、初始为空的散列表HT ,散列函数H(k) = k % 7,用线性探测再散列法解决冲突。将关键字22, 43, 15 依次插人到 HT 后,查找成功的平均查找长度是()
A. 1.5 B. 1.6 C. 2 D. 3
参考答案:C
【2014年真题】用哈希(散列)方法处理冲突(碰撞)时可能出现堆积(聚集)现象,下列选项中, 会受堆积现象直接影响的是()
A.存储效率
B.散列函数
C.装填(装载)因子
D.平均查找长度
参考答案:D
答案解析:产生堆积现象,即产生了冲突,它对存储效率、散列函数和装填因子均不会有影响,而平均查找长度会因为堆积现象而增大,选 D。
【2011年真题】为提高散列(Hash)表的查找效率,可以采取的正确措施是()
Ⅰ. 增大装填(载)因子
Ⅱ.设计冲突(碰撞)少的散列函数
Ⅲ.处理冲突(碰撞)时避免产生聚集(堆积)现象
A.仅Ⅰ
B.仅Ⅱ
C.仅Ⅰ、Ⅱ
D.仅Ⅱ、Ⅲ
解答:B。III错在“避免”二字。
【2010年真题】将关键字序列(7、8、30、11、18、9、14)散列存储到散列表中。散列表的存储空间是一个下标从 0 开始的一维数组,散列函数为:H(key) = (key*3) MOD 7,处理冲突采用线性探测再散列法,要求装填(载)因子为 0.7。
(1) 请画出所构造的散列表。
(2) 分别计算等概率情况下查找成功和查找不成功的平均查找长度。
参考答案:
(1) 由装载因子 0.7,数据总数为 7,得一维数组大小为 7/0.7=10,数组下标为 0~9。所构造的散列函数值如下所示:
|
key |
7 |
8 |
30 |
11 |
18 |
9 |
14 |
|
H(key) |
0 |
3 |
6 |
5 |
5 |
6 |
0 |
采用线性探测再散列法处理冲突,所构造的散列表为:
|
地址 |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
7 |
8 |
9 |
|
关键字 |
7 |
14 |
|
8 |
|
11 |
30 |
18 |
9 |
|
(2)查找成功时,是根据每个元素查找次数来计算平均长度,在等概率的情况下,各关键字的查找次数为:
|
key |
7 |
8 |
30 |
11 |
18 |
9 |
14 |
|
次数 |
1 |
1 |
1 |
1 |
3 |
3 |
2 |
故,ASL 成功 = 查找次数 / 元素个数 = (1+2+1+1+1+3+3) / 7 = 12/7
这里要特别防止惯性思维。查找失败时,是根据查找失败位置计算平均次数,根据散列函数 MOD 7,初始
只可能在 0~6 的位置。等概率情况下,查找 0~6 位置查找失败的查找次数为:
|
H(key) |
0 |
1 |
2 |
3 |
4 |
5 |
6 |
|
次数 |
3 |
2 |
1 |
2 |
1 |
5 |
4 |
故,ASL不成功 = 查找次数 / 散列后的地址个数 = (3+2+1+2+1+5+4) / 7 = 18 / 7


 The road of your choice, you have to go on !
粤ICP备16082171号-1
The road of your choice, you have to go on !
粤ICP备16082171号-1



登录后开始许愿
暂无评论,来抢沙发